What Is a Decision Engine? How Vitals Data Feeds Automated Underwriting Rules
A research-driven look at how a decision engine uses vitals data, rules logic, and underwriting models to automate insurance decisions inside digital platforms.
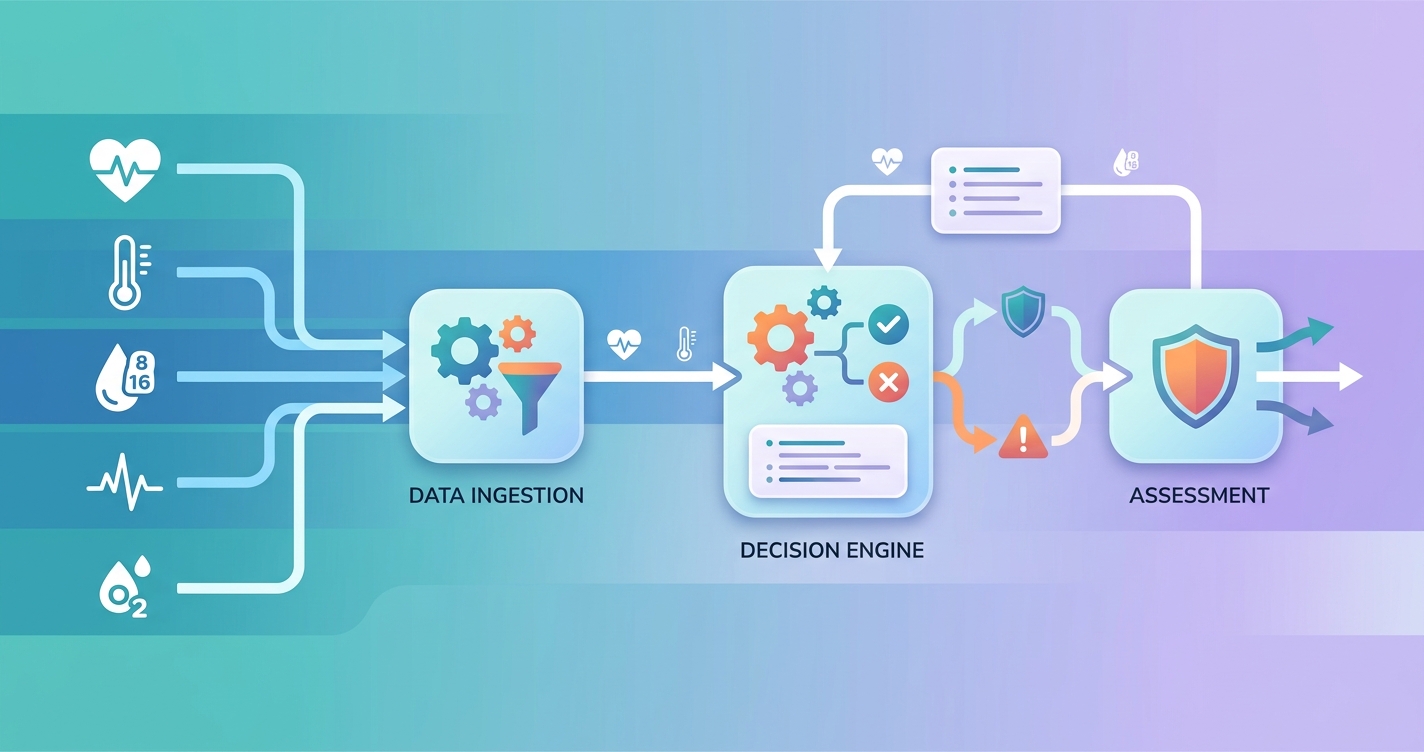
A lot of insurance teams talk about straight-through processing as if it starts with a faster rules engine. It usually does not. It starts with a cleaner decision engine: a layer that can take applicant inputs, normalize external evidence, apply underwriting logic, and return an action that downstream systems can actually use. That is why the phrase decision engine vitals automated underwriting rules matters now. Once vitals data enters digital underwriting, the real work is no longer just capture. It is orchestration.
"ACORD's Next-Generation Digital Standards are designed to support data transfer mechanisms including microservices and RESTful APIs." — Bill Pieroni, ACORD, on the release of the organization's Next-Generation Digital Standards
Decision engine architecture for vitals-based underwriting rules
A decision engine in underwriting is the layer that turns inputs into actions. It does not simply store rules. It evaluates eligibility, assembles evidence, applies thresholds, triggers referrals, logs rationale, and returns a decision payload that a distribution flow, policy admin system, or case-management team can act on.
In older environments, that logic often sat in a patchwork of hard-coded screens, spreadsheet scorecards, and manual review queues. In newer digital underwriting platforms, the engine is more explicit. It typically sits between the intake layer and the downstream systems that issue policies or route cases.
When vitals data gets added, the engine usually needs to process at least five things at once:
- the observation itself, such as heart rate or blood pressure
- the context of capture, including timestamp and session ID
- signal-quality or confidence metadata
- business rules tied to product, age band, face amount, or jurisdiction
- the output state, such as pass, refer, hold, or request additional evidence
That is the point many teams miss. Vitals are not useful because they are numerical. They are useful because they can be translated into decision-ready states.
| Decision-engine function | What it does with vitals data | Typical output | |---|---|---| | Input normalization | Converts capture payloads into standard fields, units, and timestamps | Clean underwriting input object | | Eligibility screening | Checks product, age, channel, and consent rules before scoring | Eligible, ineligible, or manual-review flag | | Rules evaluation | Applies thresholds and exception logic to vitals and related evidence | Pass, fail, refer, or evidence-order action | | Risk scoring | Combines vitals with applicant and historical data | Risk band or score | | Audit and explainability | Stores what rule fired and why | Decision trace for compliance and QA |
How vitals data feeds automated underwriting rules
Vitals data usually enters the engine as one evidence source among several, not as a standalone verdict. That is how most mature automated underwriting environments are built. The engine takes health-related observations, checks whether the data is recent and usable, and then decides how much weight to assign it.
For example, one rules path might look like this:
- confirm identity and consent
- verify the capture session meets minimum quality thresholds
- map the vitals payload into the platform's canonical schema
- compare values against product-specific underwriting rules
- combine that result with prescription, claims, or questionnaire data
- return a straight-through approval, a referral, or a request for more evidence
RGA has written for years that automated underwriting is moving away from simple rule repositories and toward broader decision-management platforms that mix rules, predictive models, and additional evidence sources. Munich Re has made the same point from another angle: its newer AI-augmented underwriting stack is designed to extend rule engines rather than replace them. In practice, that means vitals data becomes one more structured input that can sharpen or reroute the existing rules path.
The technical shift sounds small, but it changes the operating model. Once a platform can ingest vitals data in real time, rules do not have to wait for a nurse visit, an APS, or a manual triage queue before deciding what to do next.
Where a decision engine adds value
The best reason to use a decision engine is not speed by itself. It is consistency. Underwriting teams need the same input to produce the same output, with a traceable explanation, across channels and products.
That matters more when vitals are involved because health-related data tends to create branching logic quickly. A single reading may lead to different actions depending on policy size, applicant age, product line, prior disclosures, or whether the platform treats the data as corroborating evidence rather than primary evidence.
Here is the practical distinction.
| Approach | How vitals are handled | Operational result | Main drawback | |---|---|---|---| | Manual review queue | Underwriter reads reports and decides case by case | Flexible judgment | Slow and inconsistent at scale | | Basic rules engine | Compares values to static thresholds | Faster triage | Limited context and brittle exceptions | | Decision engine with models and rules | Evaluates vitals alongside identity, product, and external evidence | More consistent straight-through decisions and cleaner referrals | Requires stronger data governance | | Decision engine plus canonical health-data layer | Stores richer observation details outside the core rules path | Better interoperability and auditability | More upfront architecture work |
For insurers and platform vendors, the middle of that table is where most modernization projects stall. They can capture vitals. They can write some rules. But the system still lacks a decision layer that knows when to trust the input, when to escalate, and how to explain the outcome.
Industry applications
Digital underwriting platforms
For API-first underwriting platforms, the decision engine is usually the orchestration core. It receives the vitals payload, runs product logic, and returns a response that can be used inside a distributor workflow within the same session. That is especially useful in embedded or point-of-sale insurance where latency shapes conversion.
Carrier and reinsurer ecosystems
Reinsurers have become unusually important here. NMG Consulting reported that by the end of 2024, nearly 450 reinsurer-owned automated underwriting platforms were active globally. That is a telling number. It suggests the decision engine is no longer just carrier infrastructure. It is part of the reinsurance value chain, too, influencing how risk rules are distributed, updated, and embedded.
BPO and operations models
BPO providers tend to care less about elegant architecture diagrams and more about file flow. In that context, decision engines help by reducing the number of applications that need manual handling. Vitals data can support that workflow if the engine converts observations into clear statuses, exception codes, and referral reasons instead of dumping raw measurements into a case file.
Current research and evidence
Some of the most useful evidence on this topic comes from standards groups and underwriting operators rather than from academic trials alone.
ACORD's Electronic Health Records Standards Program is built around a simple idea: underwriting data moves better when the structure is agreed on upstream. That matters for vitals because the decision engine needs consistent fields, timestamps, provenance, and data definitions before any rule can fire reliably.
Market data suggests these decision layers are no longer niche infrastructure. NMG Consulting reported that nearly 450 reinsurer-owned automated underwriting platforms were live globally at the close of 2024, accounting for more than half of all active systems worldwide. That scale helps explain why decision-engine design now matters to carriers, reinsurers, and third-party platform vendors at the same time.
Munich Re has made the same architectural point in its writing on augmented automated underwriting. The company describes newer systems as combinations of rule engines, predictive models, and cloud-based orchestration rather than simple threshold checkers. In plain English, the rules still matter, but they now sit inside a broader engine that can weigh more evidence and adapt faster.
There is also a research reason insurers keep paying attention to richer physiological signals. In a 2022 systematic review and meta-analysis in Neuroscience & Biobehavioral Reviews, Marc N. Jarczok and colleagues analyzed 32 studies plus two individual-participant datasets covering 38,008 participants and found that lower heart rate variability measures were significant predictors of higher mortality across varied populations. That does not mean any one camera-based measurement should drive a coverage decision on its own. It does explain why physiological signals continue to attract attention as underwriting inputs instead of novelty data.
The standards side matters just as much as the science. If a vitals feed arrives without context, units, timestamps, or source metadata, the engine cannot treat it as decision-grade evidence. It becomes another messy attachment. That is why HL7 FHIR and ACORD-style insurance data structures keep showing up in real platform design conversations.
The future of decision engines in underwriting
The next phase probably looks less like one giant rules workbook and more like a layered system.
The front end will keep getting simpler for applicants. A brief capture session, fewer follow-up questions, faster referrals when needed. Behind that, the decision engine will likely get more modular:
- a rules layer for product and compliance logic
- a scoring layer for predictive models
- a canonical data layer for health observations and provenance
- an audit layer that records why a decision was made
That split makes sense. Policy systems are not great places to store every nuance of screening data, and underwriters do not want opaque model outputs with no rule trace. The engine has to bridge those two realities.
The insurers that get this right will probably be the ones that stop asking whether vitals data can be captured and start asking a sharper question: what exact decision should this data improve, and what evidence trail will support that action later?
Frequently Asked Questions
What is a decision engine in insurance underwriting?
It is the software layer that evaluates applicant information, applies underwriting logic, and returns a decision or next action. In digital underwriting, it often combines rules, eligibility checks, evidence handling, and audit logging.
How does vitals data feed automated underwriting rules?
Vitals data usually enters as structured evidence. The decision engine normalizes the payload, checks quality and eligibility, compares it against product rules, and combines it with other data sources before returning an approval, referral, or request for more evidence.
Is a decision engine the same as a rules engine?
Not quite. A rules engine applies defined logic. A decision engine usually does more: it orchestrates inputs, manages exceptions, integrates scoring models, and records the rationale behind the outcome.
Why do standards matter for vitals-based underwriting?
Because rules only work well when the incoming data is consistent. Standards and canonical schemas help the platform preserve units, timestamps, provenance, and field definitions, which makes decisions easier to audit and reuse.
For teams building digital underwriting infrastructure, solutions like Circadify's custom environments are aimed at fitting vitals capture into real decision flows rather than leaving it as a disconnected data source. Related reading: 5 Integration Patterns for Adding Vitals Data to Policy Admin Systems and FHIR vs Proprietary Formats: How to Model Health Screening Payloads.